
Doppelte Datensätze kosten Zeit, Motivation, Reputation und Geld
Was sind Dubletten?
Unter einer Dublette versteht man in Bezug auf Datenbanken einen Datensatz zu einem Objekt, der mehrfach vorhanden ist. Ihr neuer Kunde Matthias Bauer mit zwei T wurde von Ihnen in Ihre Act!-Datenbank eingetragen. Einige Zeit später telefonierte Herr Bauer mit Ihrer Kollegin, die ihn aber nicht in der Datenbank fand. Denn sie suchte nach einem Mathias Bauer mit einem T. Nach dem Gespräch hat sie den Datensatz ein zweites Mal angelegt. Mat(t)hias Bauer befindet sich nun zweimal in Ihrer Datenbank, jeweils mit unterschiedlichem Vornamen. Das ist eine Dublette.
Dubletten kosten Zeit, Motivation, Reputation und Geld!
Wenn Sie das nächste Mal nach Matthias Bauer schauen, dann sehen Sie dort nicht, dass er mit Ihrer Kollegin gesprochen hat. Das Ergebnis des Telefonates – Verabredungen, Informationen, eine Anforderung eines Prospektes oder Angebotes – befindet sich zwar in der Datenbank, aber unter Mathias, nicht unter Matthias.
Der Kunde muss wegen des fehlenden Angebotes nachhaken. Sie müssen eingestehen, dass diese Anfrage scheinbar nicht in der Datenbank vermerkt ist. Der Kunde bekommt den Eindruck, dass man in Ihrem Unternehmen schlampig arbeitet. Sie müssen mühsam im Hause ermitteln, wer denn das Gespräch mit Herrn Bauer geführt hat und wieso die Anfrage nicht im Datensatz vermerkt ist. Und Ihr Kunde bekommt derweil den teuren, neuen Katalog gleich zweimal zugeschickt.
Das alles kostet Zeit, Motivation, Reputation und Geld.
Dubletten sind nicht die Ausnahme, sie sind die Regel – und das macht sie erst so richtig teuer!
Einzelne Fälle dieser Art werden immer wieder auftreten und lassen sich auch händeln. Leider sind Dubletten nicht die Ausnahme, sie sind fast schon die Regel. Studien zufolge sind auch in gut gepflegten CRM-Datenbanken zwischen 4 und 7 Prozent der Datensätze Dubletten, also mehrfach vorhandene Kontaktdatensätze. In weniger gepflegten Datenbanken finden sich bis zu 30 Prozent Dubletten. Sie verschicken im Zweifel also nicht ein paar wenige Kataloge und Prospekte doppelt, sondern eher eine ganze Palette.
Zu viele Dubletten sind nicht nur im operativen Customer-Relationship-Management (CRM) hinderlich, sie stören auch Ihr analytisches CRM. Statt 130.000 Kunden sind es in Wirklichkeit nur 100.000, der Umsatz pro Kunde ist auf einmal nicht mehr unter Branchenschnitt, und alle Maßnahmen und damit Ausgaben, um den Umsatz pro Kunde auf den Branchenschnitt anzuheben, sind eigentlich überflüssig. Sie benötigen stattdessen eine Kampagne zur Neukundengewinnung.
Dubletten zu bereinigen kann also richtig viel einsparen – Zeit, den Verbrauch von Motivation, Schäden an Ihrer Reputation und vor allem: Geld!


Act! bringt eine einfache, statische Dublettenbereinigung mit
Die Dublette Matthias und Mathias Bauer findet die in Act! eingebaute Dublettenprüfung aber nicht. Und die weitaus meisten Dubletten sind Buchstabendreher und Varianten von Namen. Schmidt, Schmitt und Schmid. Bauer und Baur. Becker und Bäcker. Mezger und Metzger, Mayer, Meyer, Maier, Meier, Mayr, Meyr, Mair und Meir. Die Liste ließe sich fast unendlich fortsetzen.
Hier hilft Ihnen die professionelle Dublettenbereinigung unseres Add-ons DUPE|IT weiter. Mithilfe der eingebauten
Eine Datenbank, die mit der statischen Dublettenprüfung von Act! eben noch als dublettenfrei galt, zeigt dank DUPE|IT auf einmal ihr wahres Gesicht und massenhaft mehrfach vorhandene Datensätze.
Professionelle Dublettenbereinigung mit unserem Add-on DUPE|IT
Die Dublette Matthias und Mathias Bauer findet die in Act! eingebaute Dublettenprüfung aber nicht. Und die weitaus meisten Dubletten sind Buchstabendreher und Varianten von Namen. Schmidt, Schmitt und Schmid. Bauer und Baur. Becker und Bäcker. Mezger und Metzger, Mayer, Meyer, Maier, Meier, Mayr, Meyr, Mair und Meir. Die Liste ließe sich fast unendlich fortsetzen.
Hier hilft Ihnen die professionelle Dublettenbereinigung unseres Add-ons DUPE|IT weiter. Mithilfe der eingebauten Fuzzylogik, der sogenannten unscharfen Dublettenerkennung, erkennt DUPE|IT ähnliche Daten. Mat(t)hias und all die oben aufgeführten Nachnamen mit ihren Varianten werden als ähnlich erkannt und je nach Wunsch und Einstellung als Dubletten klassifiziert und zusammengeführt.
Eine Datenbank, die mit der statischen Dublettenprüfung von Act! eben noch als dublettenfrei galt, zeigt dank DUPE|IT auf einmal ihr wahres Gesicht und massenhaft mehrfach vorhandene Datensätze.
Ihre Vorteile durch den Einsatz von DUPE|IT
- Passen Sie die Kriterien und Schärfe der Dublettenerkennung selbst an!
- Finden Sie Dubletten von Kontakten und Firmen anhand ähnlicher Daten und führen Sie diese zusammen!
- Behalten Sie den perfekten Überblick über die Geschäftsbeziehungen zu Ihren Kunden, wenn es zu jedem Kunden nur einen Datensatz gibt – und nicht von manchem zwei!
- Ordnen Sie Historien, Notizen, Dokumente, Verkaufschancen, Gruppen und sekundäre Kontakte dem vereinigten Datensatz zu!
- Die Daten aus den Feldern der zusammengeführten Datensätze werden in einer Notiz des vereinigten Datensatzes als Protokoll abgelegt, sodass Sie jederzeit auf die unterschiedlichen Vorgängerdaten zugreifen können.
- Sparen Sie Kosten, indem Sie Werbebriefe und den neuen Katalog nicht zweimal an Mat(t)hias Bauer versenden.
- Liefern Sie Ihrem Kunden eine vollständige Auskunft über gespeicherte, personenbezogene Daten gemäß Datenschutz-Grundverordnung! Und nicht nur die halbe Auskunft, weil der Rest der Daten in einem zweiten Datensatz gespeichert ist.
Sparen Sie Zeit und Geld mit dem Einsatz unserer professionellen Dublettenbereinigung DUPE|IT für die CRM-Lösung Act!!
Die Dublettenerkennung mit DUPE|IT im Detail
In welchen Bereichen findet DUPE|IT Dubletten?
Mit DUPE|IT können Sie Dubletten in den Bereichen Kontakte und Firmen finden.
Welche Kriterien verwendet DUPE|IT?
Das Ergebnis einer Dublettensuche ist stark von den gewählten Einstellungen und der Qualität Ihrer Daten abhängig. Für eine größtmögliche Flexibilität stellt Ihnen DUPE|IT eine breite Palette von Einstellungsmöglichkeiten zur Verfügung.
Sie können selbst am besten entscheiden, wie gut die Qualität Ihrer Daten ist und ob Sie bereits mit dem Vergleich von E-Mail-Adressen den Großteil der Dubletten entfernen können. Oder ob Sie für die Dublettenbereinigung weitere Kriterien für weitere Datenbankfelder konfigurieren möchten.
Bei üblicher Datenqualität empfehlen Ihnen, dass Sie mehr als 3 Felder für Ihre Kriterien heranziehen. Bei Adressdaten zum Beispiel wählen Sie typischerweise Firma, Kontakt, E-Mail-Adresse, Postleitzahl und Ort.
E-Mail-Adressen sind in der Regel ein eindeutiges Merkmal, anhand derer man Dubletten klar identifizieren kann. Die Erkennung über den Kontaktnamen ist dagegen nicht immer eindeutig, da gleiche Namen auch für verschiedene Personen stehen können.
Überlegene Algorithmen
Programme zur unscharfen Dublettenerkennung setzen gerne phonetische Algorithmen wie SoundEx ein. Diese erkennen aber Permutationen nur sehr schlecht. Unter Permutationen versteht man zum Beispiel Vertauschungen wie „Emli“ statt „Emil“. Phonetische Verfahren sind zudem für bestimmte Sprachen optimiert und funktionieren mit Englisch deutlich besser als mit Deutsch.
Mustererkennungsalgorithmen wie die Levenshtein-Distanz erkennen Permutationen gut, die erforderliche Rechenzeit wächst aber quadratisch mit der Anzahl untersuchter Datensätze. Ihr Rechner kommt so schnell an seine Grenzen.
DUPE|IT setzt daher auf einen anderen Algorithmus, das FuzzyDupes-Verfahren. Es trifft mit einem Trigram-Hashindex zur Clusterbildung eine Vorauswahl an möglichen Dubletten. Diese werden dann mit einem Mustererkennungsalgorithmus, der auf die Erkennung von Permutationen spezialisiert ist, weiter untersucht. Mathematisch lässt sich zeigen, dass die verwendeten Algorithmen Ähnlichkeiten vollständig erkennen können.
Das FuzzyDupes-Verfahren ist unabhängig von Sprache und Kultur und eignet sich daher bestens für Datensätze in deutscher Sprache. Es ist parallelisiert und profitiert von Rechnern mit mehreren Prozessorkernen.
Detaileinstellungen
Clusterbildung – dazu markieren Sie etwa 2 bis 4 der gewählten Kriterien. Diese Felder sollten sehr gut mit Daten gefüllt sein. Bitte wählen Sie nur Felder vom Typ Zeichen, Postleitzahlen sind hierfür ungeeignet. Eine adäquate Auswahl für Adressdaten ist Name, Straße und Ort. Die Dublettensuche berechnet mit Hilfe von unscharfen Vergleichsalgorithmen anhand der gewählten Kriterien jeweils die Übereinstimmung.
Gewichtung – standardmäßig können Sie die Gewichtung auf Normal stehen lassen. Alternativ können Sie einzelne Felder mehr oder weniger stark gewichten.
Identität – wählen Sie die Option Identisch, wenn beim Datenvergleich eine exakte Übereinstimmung erforderlich ist. Die exakte Überprüfung funktioniert auch in Verbindung mit numerischen Werten wie zum Beispiel einer Kundennummer.
NULL-Vergleich – wählen Sie hier die Felder, die in den meisten Datensätzen Werte enthalten. Für Felder, die in Ihrer Act!-Datenbank kaum gepflegt sind, also meist keine Werte enthalten, markieren Sie NULL-Vergleich nicht.
Wie wird das Ergebnis der Dublettensuche dargestellt und weiterverarbeitet?
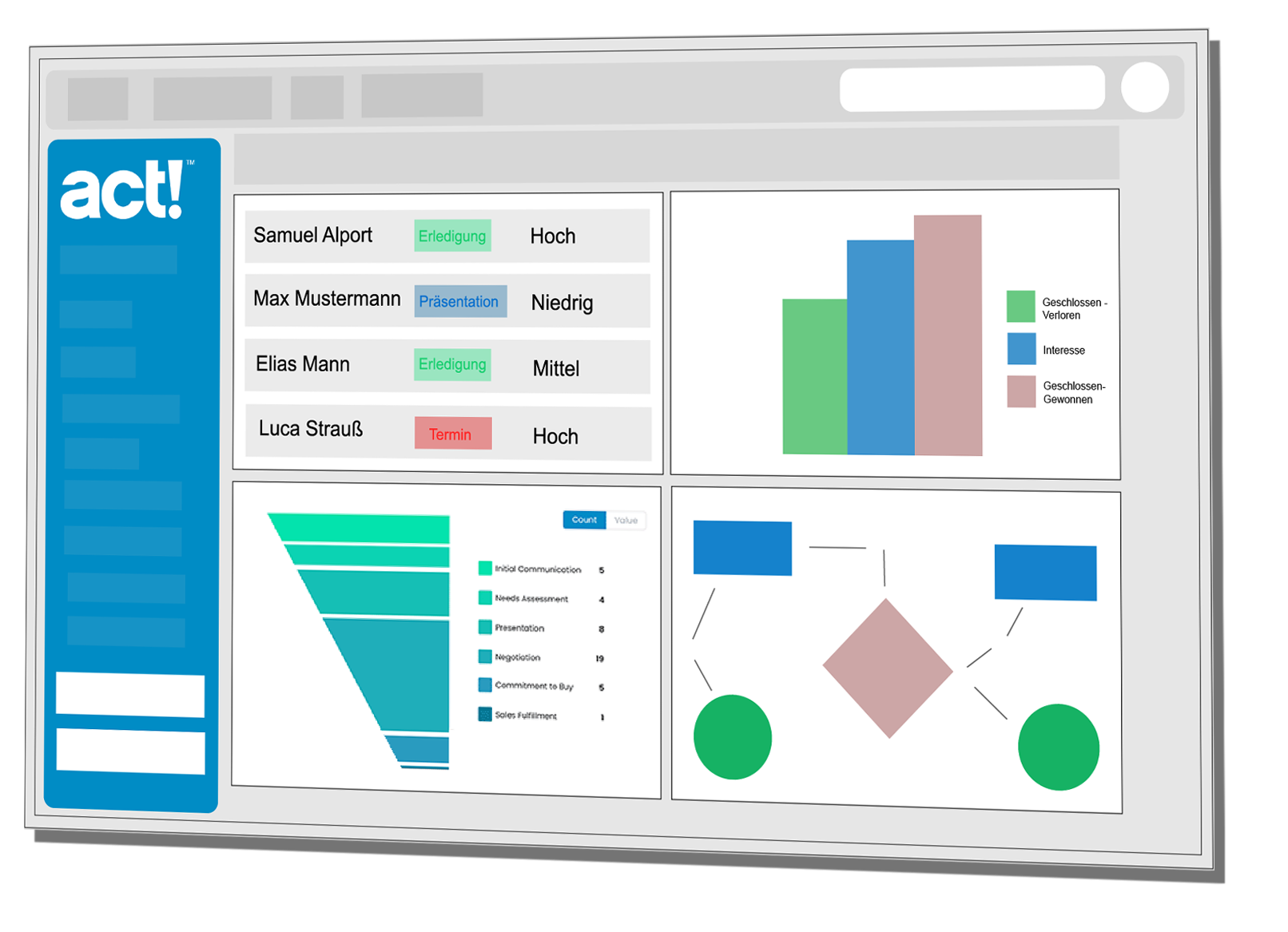
Nachdem DUPE|IT anhand Ihrer Einstellungen Ihre Datenbank auf mögliche Dubletten geprüft hat, bekommen Sie eine Liste aller ähnlichen Datensätze. Zu jedem Datensatz ist der Wert der prozentualen Ähnlichkeit in den gewählten und gewichteten Kriterien angegeben. Je näher sich dieser Wert an den 100 % befindet, desto wahrscheinlicher ist es, dass es sich um ein und denselben Kontakt (bzw. Firma) handelt. Sie können nun entscheiden, welche Datensätze Sie zusammenführen möchten.
Für die Datensätze, die zusammengeführt werden sollen, wählen Sie jeweils die Kopfdublette aus. Das ist die Dublette, die Sie behalten möchten. Die anderen Dubletten sind die Folgedubletten. Diese werden zu der zugehörigen Kopfdublette hinzugefügt.
Die Daten der Kopfdublette werden bei einfachen Feldern wie Name, Straße und Ort bevorzugt. Die Listenfelder wie die Historie und die Notizen werden jeweils zu einer gemeinsamen Liste zusammengefügt. In der Kopfdublette finden Sie dann unter Historie die bisherigen Historieneinträge der Kopfdublette und die der zugehörigen Nebendubletten. Zusätzlich wird ein Protokoll der Zusammenführung in den Notizen der Kopfdublette abgelegt, sodass Sie jederzeit nachvollziehen können, wie die Dubletten vor der Zusammenführung aussahen.
Ist eine mehrfache Dublettensuche sinnvoll?
Sie sollten die Dublettensuche nicht nur regelmäßig wiederholen, zum Beispiel einmal im Monat, sondern auch bei jedem Suchtermin mehrere Durchläufe mit verschiedenen Kriterien und Parametern starten. Sie werden überrascht sein, welche Ergebnisse Sie damit erzielen und wie viele Duplikate gefunden werden!
Faire Bepreisung
Der Preis unseres Add-ons DUPE|IT zur Dublettenbereinigung richtet sich nach der Anzahl bereinigter Dubletten, gezählt werden dabei die Kopfdubletten. Wenn Sie zum Beispiel einen Max Meier und einen M. Meier mit einem Max Meyer zusammenführen, so sind dies eine Kopfdublette und zwei Folgedubletten, für die zusammen eine Dublette berechnet wird. Sie bezahlen also genau die Leistung, die Sie auch haben möchten.
Unser Preis liegt pro Kopfdublette deutlich unter den Kosten, die durch Dubletten in einer CRM-Datenbank üblicherweise entstehen. Denn allein ein unnötigerweise doppelt versandter Katalog kostet Sie schnell mehrere Euro. Und wenn sich ein Mitarbeiter von Hand oder im Hause auf die Suche nach Dubletten macht, können Sie die Eurostücke im Minutentakt fallen hören.
Wir bieten Ihnen interessante Mengenrabatte an. Fragen Sie unseren Vertrieb nach den aktuellen Konditionen.
Sie möchten mehr erfahren?
Sie möchten mehr über unser Add-on DUPE|IT für das CRM-System Act! und die Vorteile einer professionellen Dublettenbereinigung erfahren? Rufen Sie uns an, wir beraten Sie gerne!